接下來幾個章節,會是要進入實際開發的前導觀念建置。今天想介紹稍微介紹一下響應式API。
在設計和開發 API 時,常見的實作方式主要有兩種:阻塞式 API 和 非阻塞式 API。而響應式 API 是非阻塞式 API 的進階實現,它結合了 事件驅動 (Event-Driven) 和 資料流處理 (Data Stream Processing),並內建 背壓機制 (Backpressure) 來處理高負載情境。以下將詳細介紹這些概念的具體定義與差異性。
在阻塞式 API 中,每當一個請求進入時,伺服器會指派一個執行緒來處理該請求,並且該執行緒會一直等待操作結束(如資料庫查詢或外部 API 呼叫),直到有結果返回。在這等待期間,執行緒會被「卡住」,無法處理其他請求。簡單來說,請求必須串行處理,無法同時並行進行。這裡給一個Blocking Flow範例如下
阻塞式 API 的執行流程
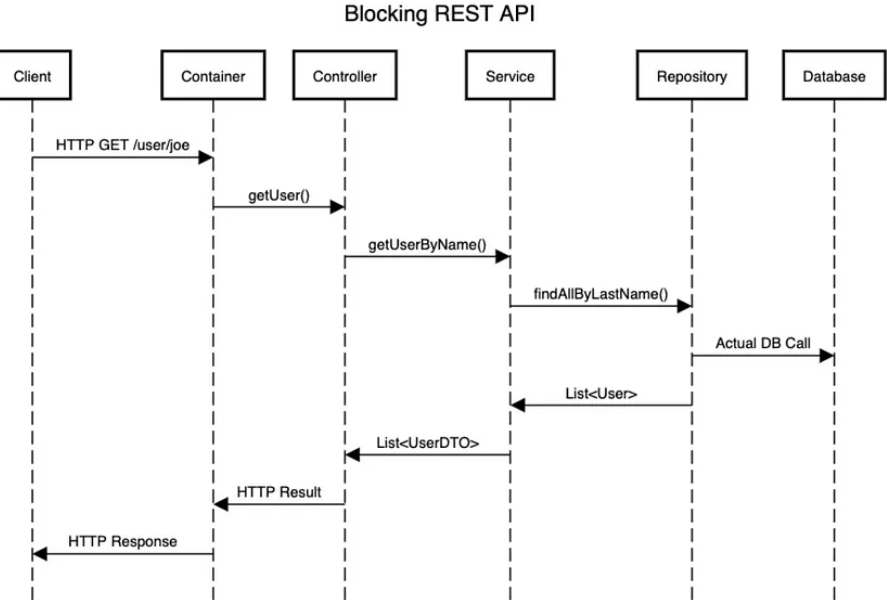
在此範例中,當用戶端發送 HTTP GET /user/joe 的請求後,伺服器在處理並回應這個請求之前,無法處理其他請求。
典型的阻塞式架構範例包括傳統的 ASP.NET Web Forms(.NET Framework)或某些工業自動化設備領域的控制系統,它們通常需要同步等待操作完成。
在非阻塞式 API 中,系統發出一個 I/O 操作後,不會等待結果回傳,而是繼續處理其他任務。當操作完成時,系統會透過 回呼 (callback) 或 Future 來接收結果。這樣可以讓執行緒在等待的過程中繼續處理其他請求,提高資源利用率。
非阻塞式 API 的非同步處理流程
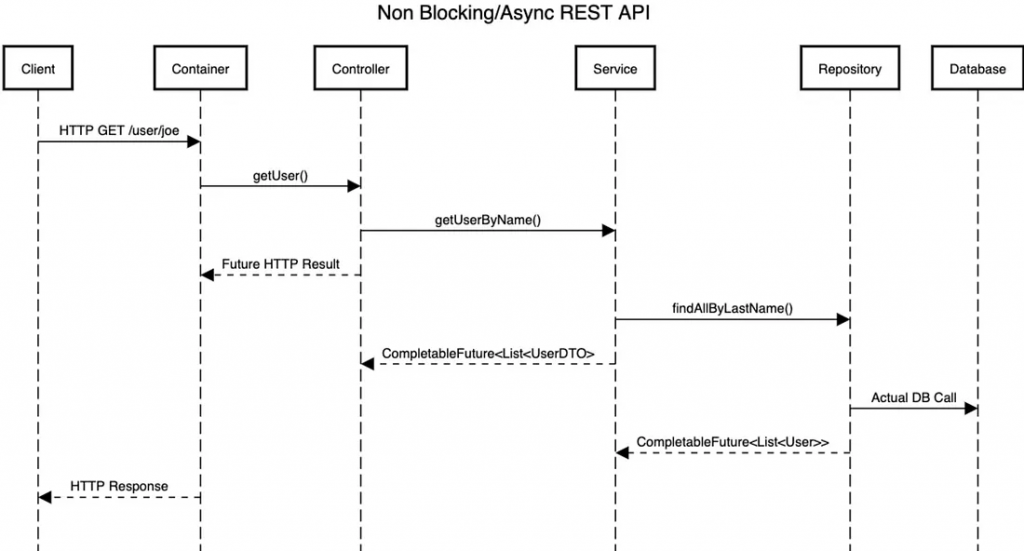
讓我們逐步分析這個流程
getUser() 方法。getUser() 調用,然後調用 Service 層的 getUserByName() 方法。getUserByName() 呼叫,進而呼叫 Repository 層的 findAllByLastName() 方法。findAllByLastName() 呼叫,然後執行實際的數據庫查詢。CompletableFuture<List<User>> 給 Service 層。CompletableFuture<List<UserDTO>> 給 Controller 層。以下是一個使用 Java CompletableFuture 實現的非阻塞範例:
@RestController
public class UserController {
private final UserService userService;
public UserController(UserService userService) {
this.userService = userService;
}
@GetMapping("/user/{name}")
public CompletableFuture<List<UserDTO>> getUser(@PathVariable String name) {
return CompletableFuture.supplyAsync(() -> userService.getUserByName(name))
.thenCompose(users -> CompletableFuture.completedFuture(users));
}
}
在純後端的情境下,非阻塞(Non-blocking) 的實現方式已經能應對大多數需求,特別是處理 I/O 等待、資料庫查詢或網絡請求等場景。而響應式是基立於Non-blocking(Thread Pool)的設計是上,並套用事件驅動(Event-Driven)和觀察者模式(Observer Pattern)設計模式。響應式程式設計可以更靈活地處理不同來源的資料流、Backpressure與Resource Elasticity。這邊以flow圖去解釋要想個情境會稍微麻煩一些,故這小節紀錄Reactive,我想說直接以應用場景對應Source Code去解釋。
響應式寫法可以輕易的讓你客製資料流串接,例如三支服務處理完後,再去做事情。
假設你正在開發一個訂單管理系統,該系統需要從不同的供應商獲取訂單數據以進行彙總和處理。這些供應商的系統是分散的,且API響應時間不同。你希望以非阻塞的方式來同步處理多個供應商的數據,並在所有數據到達後進行訂單的彙總。寫法就會如下
import io.smallrye.mutiny.Multi;
import io.smallrye.mutiny.Uni;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import java.time.Duration;
@Path("/orders")
public class OrderController {
// 模擬從供應商1獲取單一訂單資料
private Uni<String> getOrderFromSupplier1() {
return Uni.createFrom().item("Order Summary from Supplier 1")
.onItem().delayIt().by(Duration.ofSeconds(2)); // 模擬網路延遲
}
// 模擬從供應商2獲取多筆訂單詳細資料
private Multi<String> getOrderDetailsFromSupplier2() {
return Multi.createFrom().items("Item 1 from Supplier 2", "Item 2 from Supplier 2")
.onItem().delayIt().by(Duration.ofSeconds(1)); // 模擬網路延遲
}
@GET
@Path("/aggregate-orders")
public Multi<String> aggregateOrderData() {
// 串接供應商1和供應商2的數據,並返回一個彙總結果
return Multi.createBy().concatenating().streams(getOrderFromSupplier1().toMulti(), getOrderDetailsFromSupplier2());
}
}
getOrderFromSupplier1() 模擬從供應商1獲取的訂單摘要,如客戶資訊和訂單總價。使用 Uni.createFrom().item() 創建單筆資料流,延遲2秒以模擬網路延遲。getOrderDetailsFromSupplier2() 模擬從供應商2獲取的訂單詳細資料,如訂單中的商品清單,使用 Multi.createFrom().items() 創建多筆資料流,並使用1秒的延遲來模擬逐筆資料的網路延遲。aggregateOrderData() 使用 Multi.createBy().concatenating().streams() 將來自兩個供應商的資料進行串接,並返回完整的訂單資料給前端進行處理。如果上段響應式程式碼轉換成非響應式的寫法會如下
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
@Path("/orders")
public class OrderController {
// 模擬從供應商1同步獲取單一訂單資料
private String getOrderFromSupplier1() {
try {
TimeUnit.SECONDS.sleep(2); // 模擬2秒的網路延遲
} catch (InterruptedException e) {
e.printStackTrace();
}
return "Order Summary from Supplier 1";
}
// 模擬從供應商2同步獲取多筆訂單詳細資料
private List<String> getOrderDetailsFromSupplier2() {
try {
TimeUnit.SECONDS.sleep(1); // 模擬1秒的網路延遲
} catch (InterruptedException e) {
e.printStackTrace();
}
List<String> details = new ArrayList<>();
details.add("Item 1 from Supplier 2");
details.add("Item 2 from Supplier 2");
return details;
}
@GET
@Path("/aggregate-orders")
public List<String> aggregateOrderData() {
List<String> result = new ArrayList<>();
// 獲取供應商1的訂單資料,同步阻塞
String orderSummary = getOrderFromSupplier1();
result.add(orderSummary);
// 獲取供應商2的訂單詳細資料,同步阻塞
List<String> orderDetails = getOrderDetailsFromSupplier2();
result.addAll(orderDetails);
return result;
}
}
最明顯的改變會是在處理阻塞操作的方式。非響應式程式碼會同步地等待各個服務返回結果,而不是像響應式那樣非阻塞地處理資料流。
非響應式寫法中,異步的資料流控制變成同步操作,因此需要明確地等待每個服務的回應才能繼續進行下一步操作。這會使程式碼的結構更加複雜,尤其是在處理延遲時,線程會被阻塞,導致效能下降。
Back-pressure 是一種流量控制手段,當系統中的某個部分(通常是消費者)無法跟上另一個部分(通常是生產者)的速度時,消費者會發出信號,要求生產者減慢速度。換句話說,當系統過載時,響應式架構允許系統向上游(即發送請求的來源)發出信號,告訴它「慢下來!」
這邊舉個例子,關於模擬從資料庫中批量提取大量的訂單資料,並進行耗時的計算處理(如計算折扣或運費)。我們需要應用背壓策略來防止數據消費方無法跟上數據生成的速度而導致內存溢出。例子如下
import io.smallrye.mutiny.Multi;
import jakarta.ws.rs.GET;
import jakarta.ws.rs.Path;
import java.util.List;
import java.util.concurrent.CompletableFuture;
@Path("/orders")
public class OrderProcessingController {
private static final int PROCESSING_DELAY_MS = 100; // 每筆訂單處理的模擬延遲
private static final int BUFFER_SIZE = 20; // 背壓緩衝大小
@GET
@Path("/process-orders")
public String processOrders() {
// 建立訂單處理結果記錄
StringBuilder processingResult = new StringBuilder();
// 從資料庫中批量提取訂單,並應用背壓策略
Multi<Order> orders = Multi.createFrom().items(getOrdersFromDatabase().stream());
// 非同步處理訂單並應用背壓
orders.onItem().transformToUniAndMerge(this::asyncProcessOrder)
.onOverflow().buffer(BUFFER_SIZE)
.collect().asList()
.subscribe().with(ignored -> processingResult.append("All orders processed successfully."));
return processingResult.toString();
}
// 非同步處理訂單,模擬耗時操作
private CompletableFuture<Order> asyncProcessOrder(Order order) {
return CompletableFuture.supplyAsync(() -> {
try {
processOrder(order);
} catch (InterruptedException e) {
logProcessingError(order, e);
}
return order;
});
}
// 模擬處理訂單的耗時操作
private void processOrder(Order order) throws InterruptedException {
Thread.sleep(PROCESSING_DELAY_MS);
System.out.println("Processed order ID: " + order.getId());
}
// 處理時發生錯誤時的日誌記錄
private void logProcessingError(Order order, Exception e) {
System.err.println("Error processing order ID: " + order.getId() + ". Error: " + e.getMessage());
}
// 模擬從資料庫中獲取訂單
private List<Order> getOrdersFromDatabase() {
// 這裡應該是實際的資料庫操作
// 假設我們有1000筆訂單
return List.of(
new Order(1), new Order(2), new Order(3), /*...直到1000筆訂單...*/ new Order(1000)
);
}
// 訂單類別
private static class Order {
private final int id;
public Order(int id) {
this.id = id;
}
public int getId() {
return id;
}
}
}
每筆訂單的處理耗時 100 毫秒,這樣可以模擬高負載情況下的處理瓶頸。如果生成的訂單數量多於處理速度,就會觸發背壓策略,進行緩衝。
onOverflow().buffer(20) 來實現背壓機制。當訂單生成的速度超過了消費者處理速度時,系統會最多緩衝 20 筆訂單。如果緩衝已滿,後續生成的訂單會暫時停止生成,直到有緩衝空間。transformToUniAndMerge 用來將每一筆訂單的處理動作轉換成非同步操作,並且支持並行處理。CompletableFuture.supplyAsync() 模擬了耗時的處理邏輯,例如計算訂單折扣或運費,讓每個處理動作都非同步進行。指的是一個系統能夠根據實際需求,動態且自動地調整其資源使用,例如 CPU、記憶體、存儲、網路帶寬等,以最佳化系統效能和資源配置。在負載增加時,系統可以自動擴展以分配更多資源來應對需求;而當負載減少時,系統則能釋放多餘的資源,避免浪費,從而達到高效能、成本效益和可擴展性的平衡。
這邊舉一個批量處理請求並配合 Kubernetes 做到Resource Elasticity範例,以下模擬一個非阻塞的批量資料處理應用。當有大量請求進來時,應用會自動擴展,並在請求量減少時自動收縮。
package com.example.resourceelasticity;
import io.smallrye.mutiny.Multi;
import io.smallrye.mutiny.Uni;
import org.jboss.logging.Logger;
import javax.ws.rs.GET;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.core.MediaType;
import java.time.Duration;
@Path("/process")
public class ResourceElasticityController {
private static final Logger LOGGER = Logger.getLogger(ResourceElasticityController.class);
// 模擬大批量的非阻塞資料處理
@GET
@Produces(MediaType.TEXT_PLAIN)
public Uni<String> processRequests() {
LOGGER.info("Received request to process data");
// 使用 Mutiny 模擬資料流處理,處理1000個項目,每個耗時 200ms
return Multi.createFrom().range(0, 1000)
.onItem().transformToUniAndMerge(item -> processItem(item))
.collect().last()
.onItem().transform(x -> "Processing completed");
}
// 模擬單項目處理
private Uni<Integer> processItem(int item) {
return Uni.createFrom().item(item)
.onItem().invoke(i -> LOGGER.infof("Processing item %d", i))
.onItem().delayIt().by(Duration.ofMillis(200)); // 模擬處理每個項目需200ms
}
}
Mutiny reactive library 來實現非阻塞的資料處理。processRequests() 函數模擬了一個批量資料處理流程,每次處理1000個項目,並且每個項目需要耗時 200ms。這樣的非阻塞模型允許系統在負載增高時能夠有效利用資源。/process 時,系統會根據負載量動態地調整可用的資源。Kubernetes 中的 Horizontal Pod Autoscaler (HPA)
在 Kubernetes 中設定 Horizontal Pod Autoscaler (HPA)。HPA 根據 CPU 或其他指標動態擴展或縮減 Quarkus 應用的 Pod 數量。
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: quarkus-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: quarkus-deployment
minReplicas: 1
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50 # 當 CPU 使用率超過 50% 時進行擴展
最後對非阻塞式語響應式做個總結比較
非阻塞(Non-blocking):通常基於 Thread Pool(執行緒池)來實現,允許執行緒在等待 I/O 或其他操作的同時繼續執行其他任務。常用工具包括 Future、CompletableFuture 等。其主要目的在於釋放線程以提高資源利用率,但不一定關注數據流或變化的傳播。
響應式(Reactive):基於事件驅動(Event-Driven)和觀察者模式(Observer Pattern)。它更專注於數據流和變化的傳播,並且擅長處理 背壓(Back-Pressure),在高負載的情況下能控制數據流的速度。

